


This article summarizes a research paper presented at the 2014 Computation + Journalism Symposium. Meredith Broussard (@merbroussard) is an assistant professor at Temple University who teaches data journalism. See the full collection of research summaries.
By Meredith Broussard
Story ideas come from unexpected places. Often, an investigative story comes out of simple curiosity: a reporter notices something strange, wonders why it’s like that and gets it in her head to track down the reason.
Conceptually, this can be described as the reporter perceiving a conflict between what is (the observed reality) and what should be (as articulated in law or policy).
This conflict was at the heart of an investigative series I wrote about textbook shortages in Philadelphia public schools. I heard from sources that there weren’t enough textbooks to go around at Philadelphia’s public schools.
Because the same people write the textbooks and the state-mandated standardized tests, students without access to textbooks can’t achieve passing scores on the standardized tests. There should be enough books in schools.
However, what is can be seen in data from the School District of Philadelphia’s textbook inventory system. (Spoiler: it’s not good.)
The most recent installment in the series, a feature called “Why Poor Schools Can’t Win at Standardized Testing,” ran in The Atlantic in July 2014.
The piece looks like any other investigative feature story, but its backstory is computationally complex: I designed a new piece of software, which was derived from artificial intelligence software, in order to do the reporting for the piece.
The term “artificial intelligence” makes most people think of Hollywood creations: Commander Data from Star Trek, or HAL 9000 from “2001: A Space Odyssey.” In truth, “intelligent” machines do not exist. (Yet.) When computer scientists say “artificial intelligence,” they are usually referring to a specialty field inside their discipline.
The Association for the Advancement of Artificial Intelligence (AAAI) describes the field of AI as “devoted to advancing the scientific understanding of the mechanisms underlying thought and intelligent behavior and their embodiment in machines.”
The software I built for the story is a prototype for what I call the Story Discovery Engine, a new type of software that reporters can use to accelerate the process of finding investigative story ideas on public affairs beats such as education, transportation or campaign finance.
A newsroom can create a single Story Discovery Engine and use it to uncover multiple stories on a beat. Instead of a single data analysis resulting in a single story, the Story Discovery Engine is a single data analysis that creates dozens of data visualizations, each of which can result in a story.
The software doesn’t spit out story ideas; rather, the reporter uses the reporting tool to generate a set of data visualizations that allow the reporter to quickly spot anomalies worthy of further investigation. She then applies her own domain knowledge and comes up with a brand-new story idea.
The Story Discovery Engine is derived from a type of artificial intelligence software called an expert system. As originally conceived in the 1970s, an expert system was supposed to be a sort of advice guru in a box that would help people make decisions. Expert systems never really took off, in part because the human brain is already pretty good at making decisions. It turns out that brains are better equipped to deal with uncertainty and complex situations than machines are.
However, one of the many interesting things about an expert system is the fact that it is based on rules. Given a set of logical rules, an expert system can apply the rules to a pool of data and flag cases where the rules are true or false. Here is a diagram of a traditional expert system, followed by a diagram of the Story Discovery Engine:
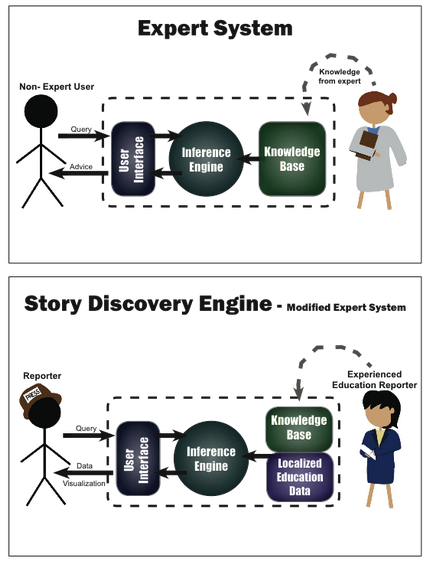
A depiction of a traditional expert system compared with the Story Discovery Engine. Graphic by Meredith Broussard & Marcus McCarthy.
The Story Discovery Engine is based on the idea that it is possible to take some of the experienced reporter’s knowledge, abstract out the high-level rules or heuristics, and implement these rules in the form of database logic. The data about the real world is fed in, the logical rules are applied, and the system presents the reporter with a visual representation of a specific site within the system (in this case, the site is a school). This visual representation triggers the reporter’s creative process and allows him to quickly discover an idea for an investigative story.
Public affairs reporting is ideally suited to the Story Discovery Engine model because what should be can be expressed in logical rules derived from laws and policies. The software compares this to what is (in this case, education data), and shows how well (or how poorly) the rules are working in practice.
Because education is standardized across the U.S. right now, the same analysis can easily be applied to any other school district. I ran my original analysis on Philadelphia, but the same software could be used to find book shortages or stories in New York, Washington, D.C., Los Angeles, or any other city. The stories that would come out of the analysis would be different depending on the situation in each district.
The reporting tool and several stories I wrote out of it are online at stackedup.org. Readers can use the search box on the right to explore the data about Philadelphia public schools, look at test scores, judge whether schools seem to have enough books, and calculate the cost of remedying any shortfall. Read through the stories and check some schools; it’s likely that you’ll come up with questions that will result in a story idea of your own.




Leave a Comment