


This article summarizes a research paper presented at the 2014 Computation + Journalism Symposium. Paul Resnick is a professor at the University of Michigan School of Information. See the full collection of research summaries.
By Paul Resnick
Information spreads on social media. So does misinformation.
To track the advance of questionable information, we need the ability to systematically monitor the dispersion of information on social media. How can journalists find what’s being distributed — and understand who it may have reached — when more than 400 million tweets are sent on a typical day?
My research team has developed some tools that may help. One is a detector that automatically mines Twitter’s public tweets and finds tweet clusters that seem to be spreading disputed, fact-checkable claims (or rumors, for shorthand).
Our detector searches for expressions of skepticism (e.g., “Is this true?”) When three tweets with similar texts express skepticism, we call it a “candidate rumor.”
Of course, this technique is not guaranteed to find every true or false rumor that circulates on Twitter, but it picked up about 90 per day running during a recent, somewhat uneventful month. (Most were related to celebrities, of course).
On a dataset of tweets related to the Boston Marathon bombing, our detector found 110 distinct rumors, far more than those that received media coverage. Moreover, candidate rumors were detectable, on average, just ten minutes after the first tweet about them.
The detector is not sufficient on its own. It requires humans to assess the candidate rumors that it detects. It’s impossible for journalists to sift through 400 million tweets a day. But it is quite manageable for professional journalists or citizen journalists to assess 100 or so candidate rumors per day.
The image below shows a screenshot of a prototype web site we are developing that would allow citizen journalists to screen the candidate rumors. Like Reddit, users can upvote or downvote those that they think are interesting enough to merit further investigation. Unlike Reddit, which depends on users to notice and submit stories, the detector automatically finds the candidate rumors.
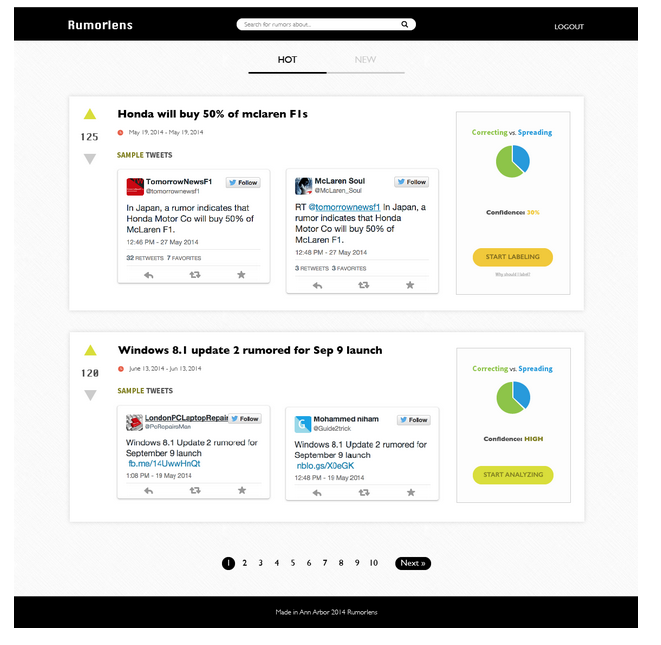
A screenshot of RumorLens, a prototype website that will allow citizen journalists to screen possible rumors spreading on Twitter. The box for each candidate rumor includes a couple of sample tweets. The right side indicates the progress of the retrieval and classification process needed to do audience analysis.
Once a target rumor is identified, it is helpful to analyze its audience. Some rumors may have reached too small an audience to be worth investigating or reporting on at all. In other cases, the dissemination patterns may themselves be worthy of investigation and reporting.
To enable audience analysis, we need to collect all the relevant tweets and classify them as either spreading or correcting the rumor. Doing so can present a challenge. For example, a journalist tracking rumors related to this year’s unrest in Ferguson, Missouri through the “#IfTheyGunnedMeDown” Twitter hashtag, might never have discovered the segment of Twitter users expressing roughly the opposite sentiment with the “#WeAreDarrenWilson” hashtag. It is easy to get some example tweets through the Twitter search engine, but comprehensive retrieval is a very difficult task.
Again, computation can reduce the amount of labor required, but some human intervention is needed. My team has developed an interactive retrieval and classification system. The system automatically generates related queries to find additional tweets that may be related to the rumor.
People provide judgment labels for some tweets: whether it spreads the rumor, corrects it, or is unrelated to the rumor. These labeled tweets are used to automatically “train” a computer program, a classifier. That program can then automatically classify other tweets.
By carefully choosing a small subset of the tweets for labeling (approximately 200 tweets for each rumor), the system achieves high accuracy while still collecting and classifying the potentially thousands of tweets related to a particular rumor.
Once the tweets have been collected, computation again aids in the audience analysis. We automatically download the follower lists of all the people who tweeted and compute intersections among them. The follower lists do not tell us who actually viewed tweets. They do, however, enable estimates of who was potentially exposed.
For the casual analyst, the system simply tallies how many people were potentially exposed to rumor tweets, correction tweets, or both. Interestingly, we found several cases where correction tweets reached large audiences, but the wrong audiences: almost no one who received the rumor also received a correction.
An analyst who wants to delve more deeply can use a more complex, interactive visualization system to explore time periods when the rumor or correction were most actively disseminated, identify individual people who were influential tweeters, and assess whether the correction tweets had any effect in reducing the spread of the rumor tweets. One component includes a Sankey diagram (not pictured) that makes it easy to see the audience overlap for rumors and corrections. The image below shows another component, a network diagram with node size depicting the number of followers of each tweet author.
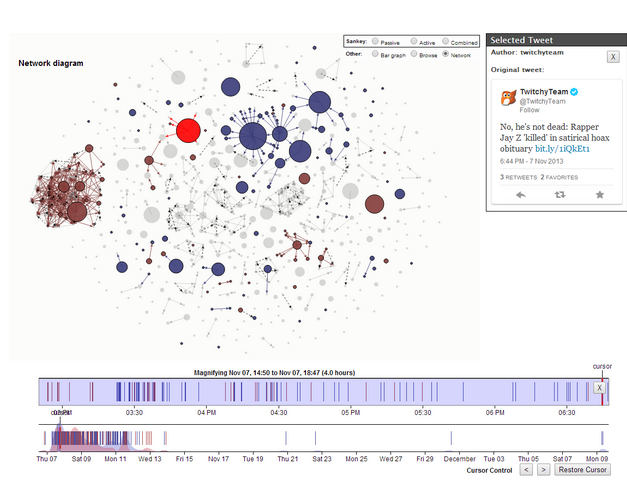
Each blue circle represents one person who tweeted the rumor; each red circle represents a person who tweeted the correction. Brown circles represent people who tweeted both. The circle size reflects the number of followers each person has. The bottom shows a timeline of the tweets sent. Selecting a subset of the timeline causes the upper diagram to gray out all the nodes not in that time window.
The same audience analysis system could be used more broadly, not just for rumors and corrections. For example, it could be used to assess the audience shares for mentions of opposing political candidates.
Rumor detection and audience analysis are only a small piece of the puzzle. Journalists will still need to investigate the veracity of contested claims.
Still, rumor detection and audience analysis are important pieces. New computational tools are opening the possibility of doing them on a routine basis. We will be making our version of these tools available through the website rumorlens.org.
It appears, however, that some human labor will still be required. Computers will not be able to perform these tasks in a completely automated fashion. It is time to start thinking about how that human labor might be recruited and organized. What might professional journalists be willing to do and how might citizen journalists be recruited to do the rest?



Leave a Comment